服务链路追踪
[一]概述
Dante Cloud 提供两种链路追踪的方案:Skywalking 和 Micrometer
[1]Skywalking
Skywalking 是分布式系统的应用程序性能监视工具,专为微服务、云原生架构和基于容器(Docker、K8s、Mesos)架构而设计。SkyWalking 是观察性分析平台和应用性能管理系统。提供分布式追踪、服务网格遥测分析、度量聚合和可视化一体化解决方案。
使用 Skywalking 方案,建议与 Dante Cloud 提供的基于 ELK 的日志聚合分析方案一起使用。因为个人观点,Skywalking 也是比较重量级的组件,主要原因是:
- 一方面,全链路的监控数据会非常多,常规关系数据库对这类数据的支持能力远不如NoSQL数据库。而 ELK 中的 ElasticSearch 又是 Skywalking 比较推荐使用的数据存储方式。
- 另一方面,为了保证追踪数据的全面,除了系统代码外,还需要在工程运行环境中增加大量的 Agent 依赖。如果是打包运行,比如说 Docker,不仅会大大增加包体的大小。而且依赖大量的 Agent,必然会对系统性能有所损耗。
但是,有点也显而易见,监控的内容丰富、系统组件成熟、链路层次多样。所以,建议硬件资源充裕的用户使用。
[2]Micrometer
Micrometer 为 Java 平台上的性能数据收集提供了一个通用的 API,它提供了多种度量指标类型(Timers、Guauges、Counters等),同时支持接入不同的监控系统,例如 Influxdb、Graphite、Prometheus 等。我们可以通过 Micrometer 收集 Java 性能数据,配合 Prometheus 监控系统实时获取数据,并最终在 Grafana 上展示出来,从而很容易实现应用的监控。
从 Spring Boot 3 开始,Spring Boot 中用于链路追踪的旧 Spring Cloud Sleuth 解决方案将替换为新的 Micrometer 库。
Micrometer 已经内置于 Spring Boot 中,使用起来非常方便,观测数据也很容易与 Zipkin、Grafana Loki 或 Datadog 等观测云集成。但毕竟算是一个新组件,整体的生态以及可观测内容的丰富程度不如老牌组件成熟。
[二]使用Skywalking
[1]Skywalking搭建
搭建 Skywalking 之前,请提前搭建好 ELK 或者 ElasticSearch。
为了方便使用 Docker Compose 脚本进行 Skywalking 的搭建。
services:
sky-oap:
image: apache/skywalking-oap-server:9.7.0-java17
container_name: skywalking-oap
hostname: skywalking-oap
ports:
- "11800:11800"
- "12800:12800"
environment:
SW_STORAGE: elasticsearch
SW_STORAGE_ES_CLUSTER_NODES: elk:9200
TZ: Asia/Shanghai
sky-ui:
image: apache/skywalking-ui:9.7.0-java17
container_name: skywalking-ui
hostname: skywalking-ui
depends_on:
- sky-oap
ports:
- "8878:8080"
environment:
SW_OAP_ADDRESS: http://oap:12800提示
第一次运行 Skywalking,建议 Skywalking 和 Skywalking UI 分开运行。先运行 Skywalking,Skywalking 正常链接 ElasticSearch 之后,会创建数据存储表,这个过程会需要一定的时间。如果数据表没有建完,启动 Skywalking UI 也无法正常使用。
[2]数据上报Skywalking
服务运行各类数据,想要上报至 Skywalking,需要依赖于 Skywalking 的 Agent。
- 如果你是本地开发运行,那么需要把 Skywaking Java Agent 加入到服务运行的 classpath 中。
- 如果使用 Docker 运行服务,那么在打包服务 Docker 时,需要把 Skywaking Java Agent 和 Plugin 与服务打包在一起。
在 Dante Cloud 中,可以将 Skywalking Java Agent 和 Plugin ,放入到工程的 ${project_home}/configurations/docker/context/agent 目录下。使用 production Profile (多环境) 进行打包,就会自动将 Skywaking Java Agent 和 Plugin 与服务打包在一起。
Skywaking Java Agent Plugin 是根据 Java 常用组件进行对应定义的。根据系统使用的组件,添加不同的 Plugin 就可以采集不同的监控数据,也可以根据实际需求自主添加或者删减 Plugin。
Dante Cloud 默认推荐添加的 Plugin 如下:
- apm-elasticsearch-7.x-plugin-9.2.0
- apm-gson-2.x-plugin-9.2.0
- apm-hikaricp-3.x-4.x-plugin-9.2.0
- apm-httpclient-5.x-plugin-9.2.0
- apm-hutool-http-5.x-plugin-9.2.0.jar
- apm-jackson-2.x-plugin-9.2.0.jar
- apm-jdbc-commons-9.2.0.jar
- apm-kafka-plugin-9.2.0.jar
- apm-lettuce-5.x-plugin-9.2.0.jar
- apm-mybatis-3.x-plugin-9.2.0.jar
- apm-mysql-8.x-plugin-9.2.0.jar
- apm-okhttp-4.x-plugin-9.2.0.jar
- apm-postgresql-8.x-plugin-9.2.0.jar
- apm-redisson-3.x-plugin-9.2.0.jar
- apm-spring-annotation-plugin-9.2.0.jar
- apm-spring-cloud-feign-2.x-plugin-9.2.0.jar
- apm-spring-cloud-gateway-3.x-plugin-9.2.0.jar
- apm-spring-kafka-2.x-plugin-9.2.0.jar
- apm-springmvc-annotation-5.x-plugin-9.2.0.jar
- apm-spring-webflux-5.x-plugin-9.2.0.jar
- apm-toolkit-kafka-activation-9.2.0.jar
- apm-toolkit-log4j-2.x-activation-9.2.0.jar
- apm-toolkit-logback-1.x-activation-9.2.0.jar
- apm-toolkit-trace-activation-9.2.0.jar
- apm-undertow-2.x-plugin-9.2.0.jar
- apm-undertow-worker-thread-pool-plugin-9.2.0.jar
提示
Skywalking Java Agent 【下载地址】
服务运行成功之后,就可以看到如下看到各类数据:
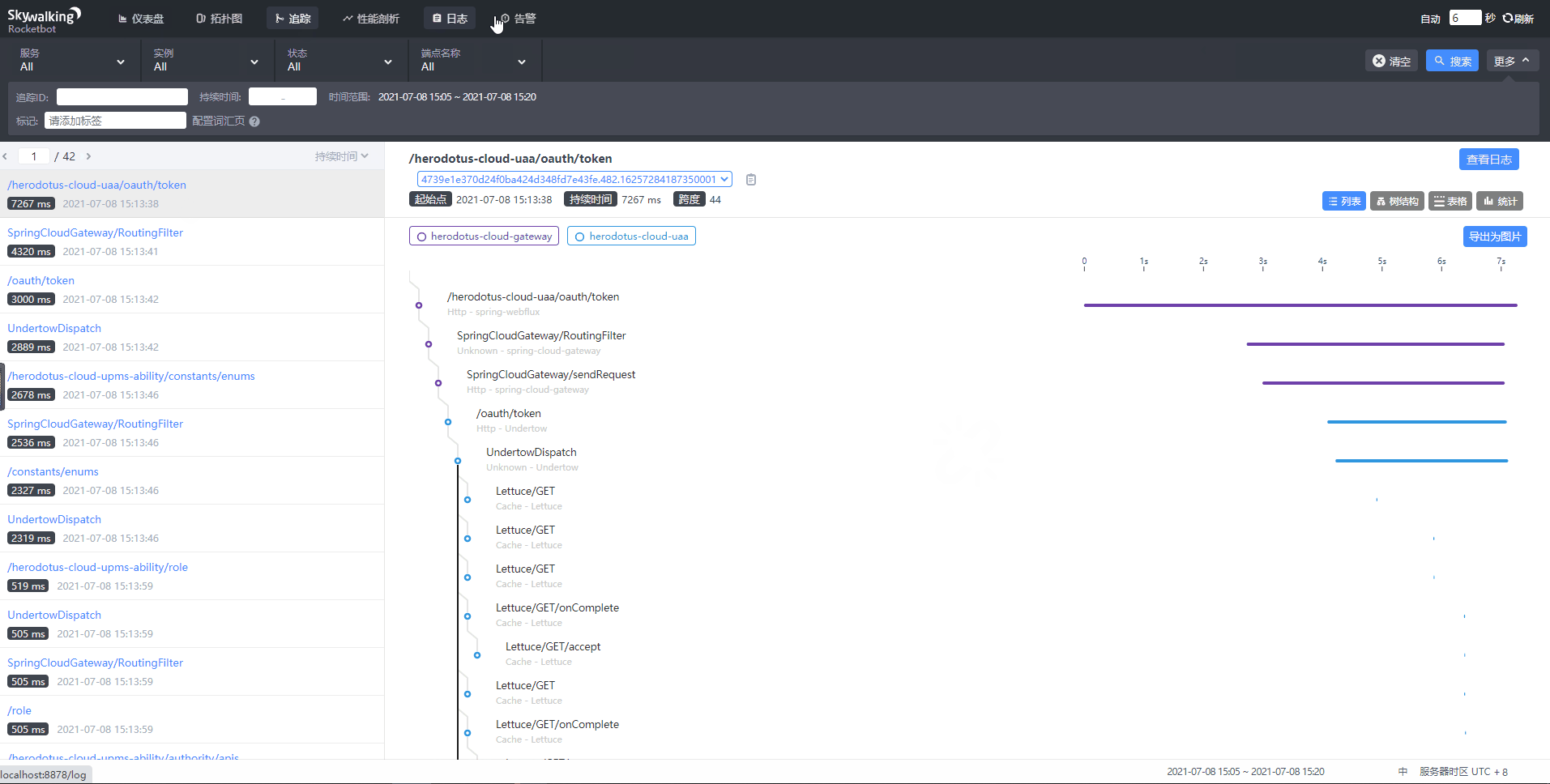
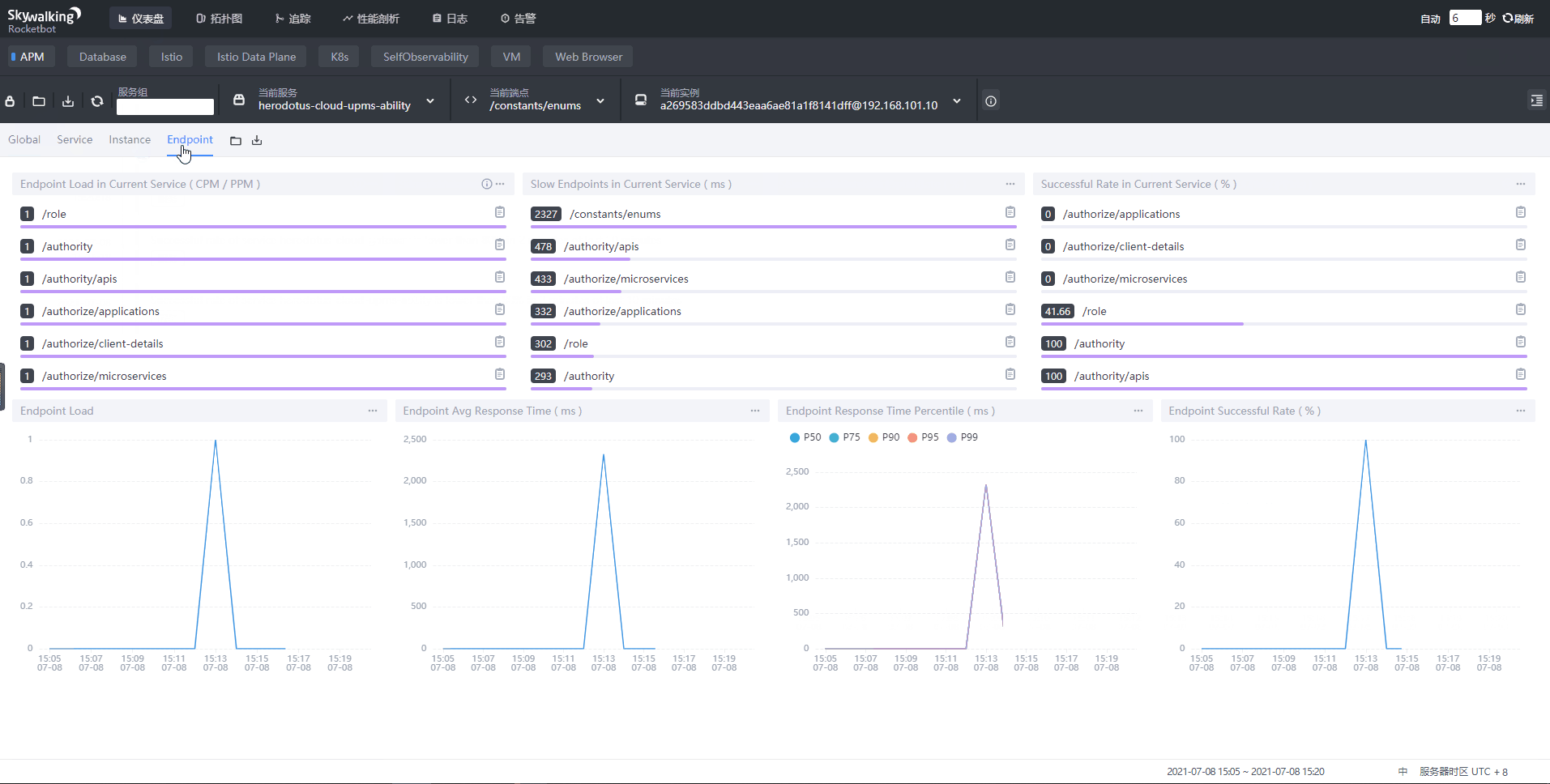
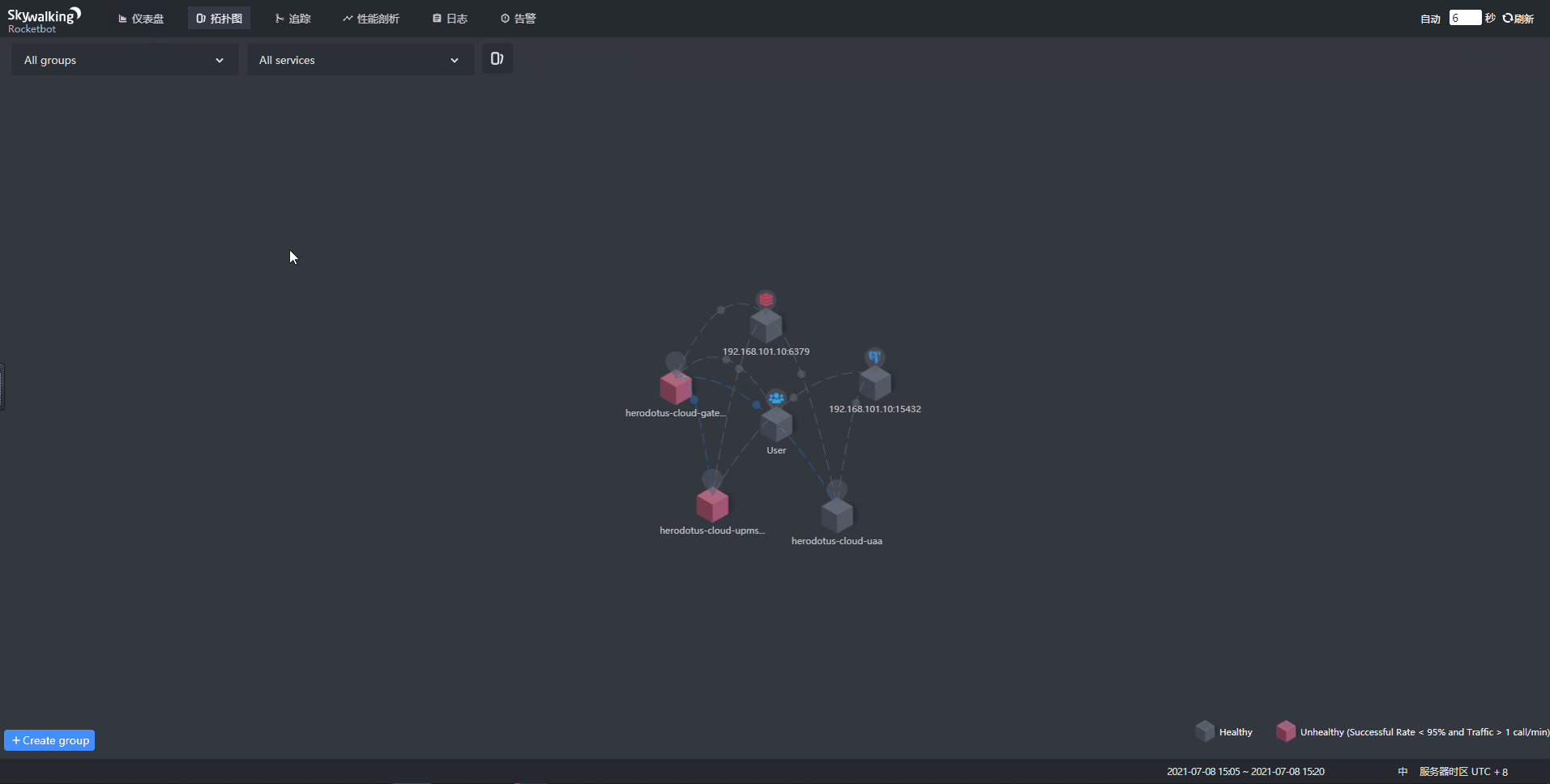
[3]注意事项
因为 Skywalking 是完全采用独立的数据埋点和数据采集体系,而且相关 Agent Plugin 是独立于工程代码之外的。所以在使用 Skywalking 体系时,需要去除工程中对 micrometer-spring-boot-starter 模块的依赖。
[三]使用Micrometer
[1]修改依赖
在 Dante Cloud 中,如果要开启 Micrometer 度量支持,只需要在工程代码中,添加 micrometer-spring-boot-starter 模块即可。建议在主工程的 facility-spring-boot-starter 中添加。
[2]使用 Zipkin
Micrometer 可以很容易的与 Zipkin 进行集成。可以使用 Zipkin 作为链路追踪的数据存储和观测工具。
选择存储
Zipkin 最初是为了在 Cassandra 上存储数据而构建的。除了Cassandra,我们原生支持ElasticSearch和MySQL。
搭建 Zipkin
这里使用 Docker Compose 搭建 Zipkin
zipkin:
image: quay.io/herodotus-cloud/zipkin:3.4.0
container_name: zipkin
hostname: zipkin
ports:
- "9411:9411"
environment:
TZ: Asia/Shanghai
STORAGE_TYPE: mysql
MYSQL_HOST: 192.168.101.10
MYSQL_TCP_PORT: 13306
MYSQL_DB: zipkin
MYSQL_USER: zipkin
MYSQL_PASS: zipkin上面 Docker Compose 使用 MySQL 作为存储仅是示例,请结合自己的实际需求选择合适的数据存储。
运行验证
Zipkin 搭建完成之后,就可以运行系统服务进行验证。系统服务正常启动之后,可以在前端界面中进行简单的操作。回到 Zipkin 的观测界面,就可以看到服务以及链路情况,如下图所示:
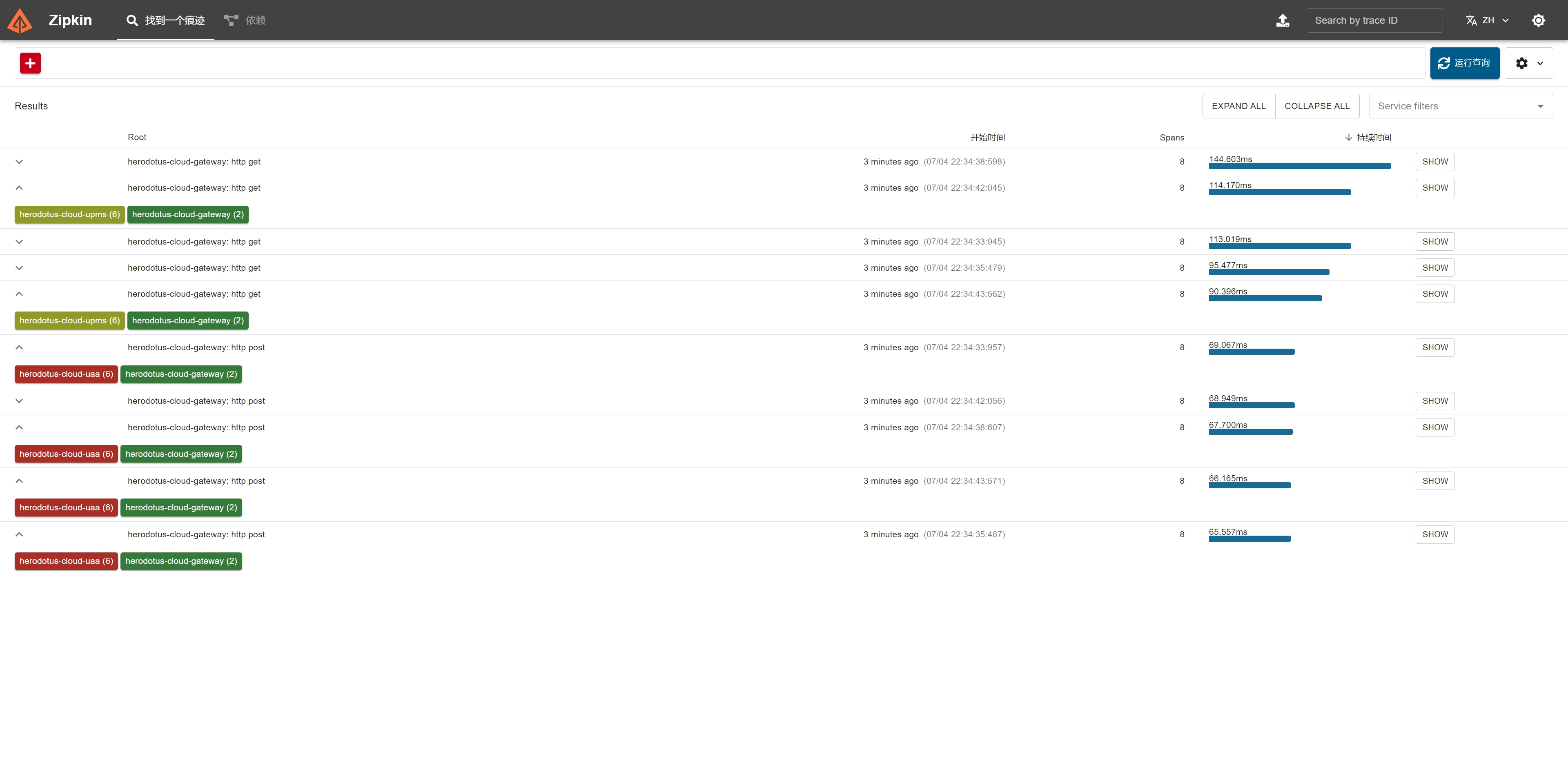
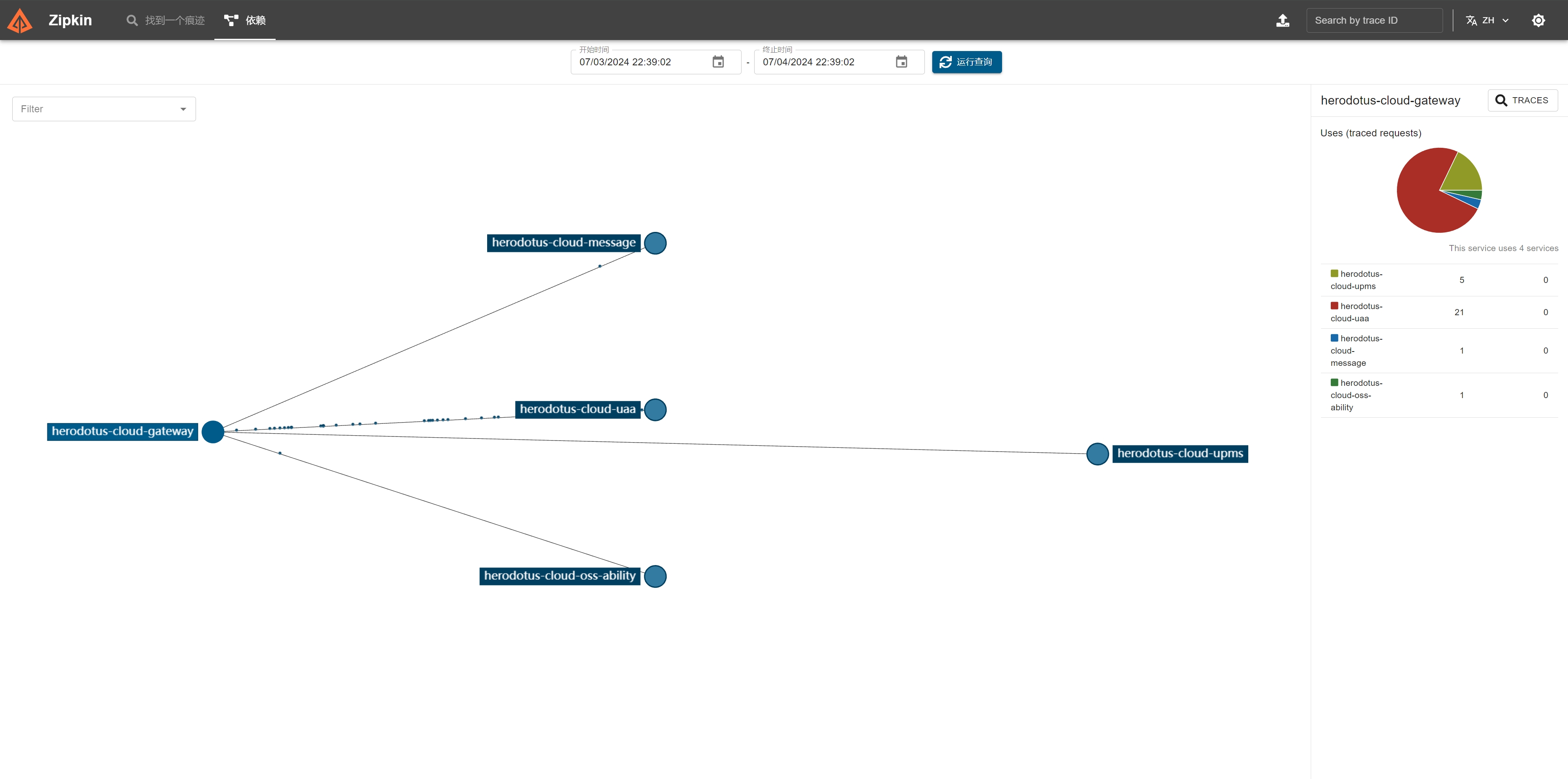
[3]使用 Tempo 和 Minio
Tempo是Grafana Labs在ObservabilityCON 2020大会上新开源的一个用于做分布式式追踪的后端服务。它和Cortex、Loki一样,Tempo也是一个兼备高扩展和低成本效应的系统。
Tempo本质上来说还是一个存储系统,它兼容一些开源的trace协议(包含Jaeger、Zipkin和OpenCensus等),将他们存在廉价的S3存储中,并利用TraceID与其他监控系统(比如Loki、Prometheus)进行协同工作。
创建存储桶和 AccessKey
这里我们使用 Minio 来存储链路追踪以及度量的相关数据。
- 新建一个 Bucket (存储桶),用于存放日志数据
- 新建一个 AccessKey,用于 Tempo 访问 Minio
如果您选择了使用 Loki 方案来存储和聚合日志,并且已经按照文档【日志数据聚合】,搭建和配置了环境,那么就可以直接使用之前新建的 AccessKey,而不需要重新创建 AccessKey
编辑配置文件
与 Loki 一样,运行和使用 Tempo 之前,也需要先编辑配置文件,然后将配置文件放到 Docker 映射的 volumes 目录下。如果没有创建配置文件或者配置文件中的配置内容错误,Tempo 很有可能无法正常启动。
在 Dante Cloud 主工程的 ${project_home}/configurations/scripts/tracing/tempo 目录下找到 tempo.yaml, 进行简单修改就可以使用。
运行 Tempo
Tempo 配置文件修改完成并且放入到指定目录后,就可以使用下面的 Docker Compose 脚本运行 Tempo
services:
tempo:
image: quay.io/herodotus-cloud/tempo:2.5.0
container_name: tempo
command: ["-config.file=/etc/tempo.yaml"]
volumes:
- D:\\local-cached\\docker-volumes\\tempo\\config\\tempo.yaml:/etc/tempo.yaml
- D:\\local-cached\\docker-volumes\\tempo\\data:/var/tempo
ports:
- "14268" # jaeger ingest
- "3200:3200" # tempo
- "9411:9411" # zipkin提示
这里需要注意的是 Tempo 开放的端口。因为 Tempo 支持自Jaeger、Zipkin和OpenCensus协议的数据采集,所以除了自身应用的默认端口 3200 以外,其它不同的端口就用于接收不同协议的数据。
例如:9411 这个端口就是 Zipkin 的默认端口,也就意味着可以利用这个端口接收来自 Zipkin 数据采集组件的数据。换句话说,因为使用了同样的端口和协议,Tempo 和 Zipkin 可以随意切换,而无需做任何修改。
运行验证
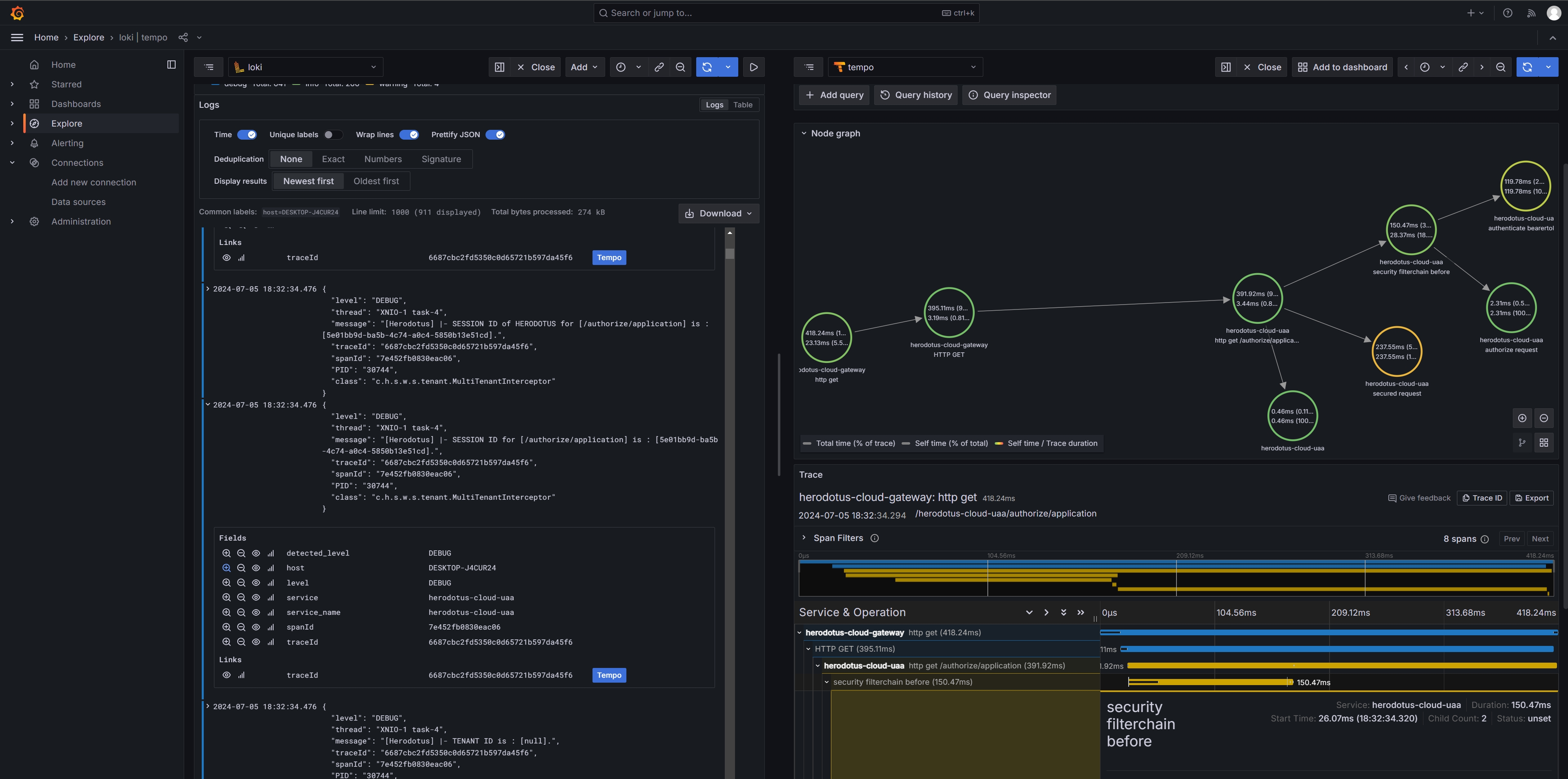
Tempo 搭建完成之后,并且正常运行之后,运行系统服务进行验证。系统服务正常启动之后,可以在前端界面中进行简单的操作。还是使用 Grafana,配置了 Tempo 数据源之后,就可以看到服务以及链路情况。
同时,在 Grafana 中,可以将 Loki 数据与 Tempo 进行关联。根据 Loki 数据中的 TraceId,就可以关联查看对应的请求链路信息。如下图所示: